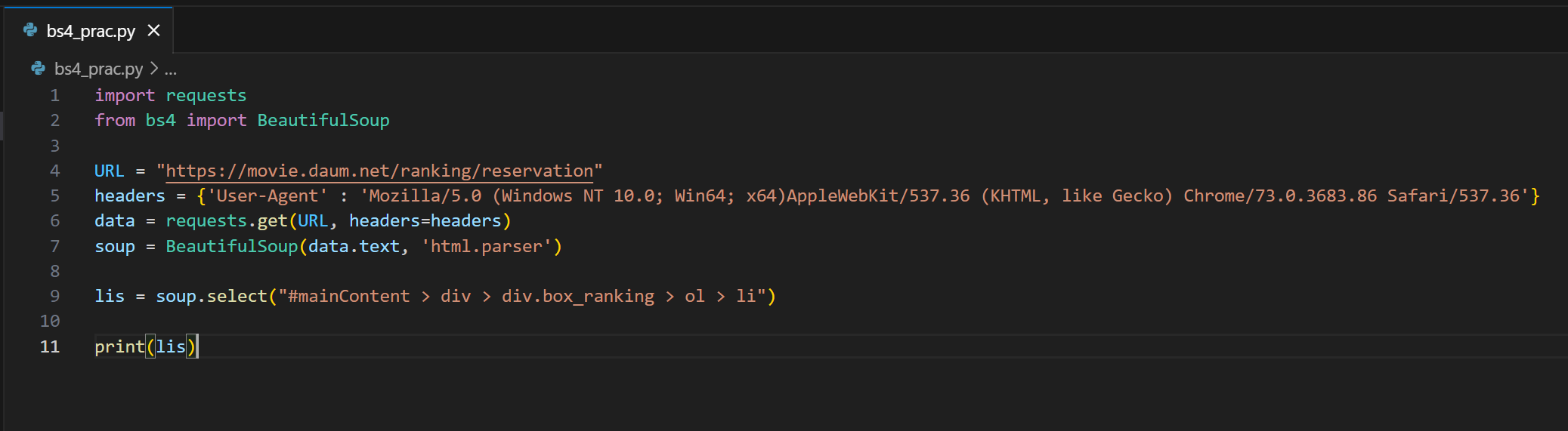
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one("#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a")
print(title.text)
soup.select_one("선택자 복사해온 내용")
태그 안의 텍스트를 가져오고 싶을 때 : 태그.text
태그 안의 속성을 가져오고 싶을 때 : 태그['속성']
제목만 가지고 오는 것을 확인할 수 있다.
2) select
검사 창을 보면 <li></li>가 영화 하나하나임을 알 수 있다.
<li></li> 하나씩을 리스트 상태로 가지고 와서
하나씩 돌면서 원하는 정보만 가지고 오면 되겠다!
select_one에서 가지고 왔던 selector의 값을 보면 li 밑으로 특정한 부분을 가지고 옴을 알 수 있는데 이 부분을 지우고 딱 li 들을 가지고 오도록 수정할 수 있다
마지막에 보면 </li>] 리스트 형태임을 알 수 있다!
<li></li> 안에서의 내가 가지고 오고 싶은 데이터의 class 명을 가지고 데이터를 뽑기!
리스트명.select_one('.class명')
lis = soup.select("#mainContent > div > div.box_ranking > ol > li")
for li in lis :
title = li.select_one('.link_txt')
print(title.text)
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
#body-content > div.newest-list > div > table > tbody > tr 로 만들어주기
import requests
from bs4 import BeautifulSoup
URL = "https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select("#body-content > div.newest-list > div > table > tbody > tr")
2) 순위
<td class="number"> ➡️ <tr> 들이 들어간 리스트에서 바로 아래 단위는 <td>
이 항목을 가져올 때는 바로 class 명만 입력해줘도 괜찮음
단, 내용이 길어서 .text[0:2]로 내용을 끊어줘야 함
for a in trs:
num = a.select_one('.number').text[0:2].strip()
3) 곡 제목, 가수명
<td class="info"> <a href="a" class="title ellipsis" ...> ➡️ td.info (상위 클래스) > a.title.ellipsis (하위 클래스) (주의) 태그명.클래스명 으로 넣어줘야 찾는다!!! 지금은 <tr> 태그로 돌리고 있는데, <tr> 태그에 붙은 클래스면 바로 .class명 으로 쓸 수 있지만 우리가 내용을 가져올 애들은 그 아래에 있는 태그에 들어있으므로 다 일일히 알려줘야함!!
import requests
from bs4 import BeautifulSoup
URL = "https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select("#body-content > div.newest-list > div > table > tbody > tr")
for a in trs:
num = a.select_one('.number').text[0:2].strip()
title = a.select_one('td.info > a.title.ellipsis').text.strip()
artist = a.select_one('td.info > a.artist.ellipsis').text.strip()
print(num, ' | ', title, ' - ', artist)