
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- get요청
- 타이타닉예제
- 서비스기획
- 당뇨병발병률예제
- 제이쿼리
- requests패키지
- 직무부트캠프후기
- 자바스크립트
- 로컬개발환경
- 데이터분석
- IT부트캠프후기
- 항해99 PM코스
- javascript
- 항해99
- 서비스기획부트캠프
- CSS
- fetch
- js
- PM코스 후기
- 프로덕트매니저
- PM코스후기
- venv설치
- jQuery
- 항해99PM코스
- HTML
- 파이썬
- PM부트캠프 후기
- temp_html
- 웹프로그래밍
- PYTHON
Archives
- Today
- Total
노엘의 샴슈
[2] Pandas와 Matplotlib 이용한 분석 예제 : 타이타닉, 당뇨병 예제 본문
1. 데이터 분석 순서
더보기
1) 문제 정의 및 가설 설정하기
2) 데이터 분석 기본 세팅하기
3) 데이터 분석하기
4) 분석 결과 시각화하기
5) 최종 결론 도출하기
예제1) 타이타닉 사례
더보기
1) Pandas 사용 선언하기
import pandas as pd
2) 데이터 가지고 오기
- 파일 업로드 버튼을 눌러 파일을 올려줍니다.
- 데이터를 파이썬에서 읽어줍니다.
변수명 = pd.read_table('파일경로', sep=',')
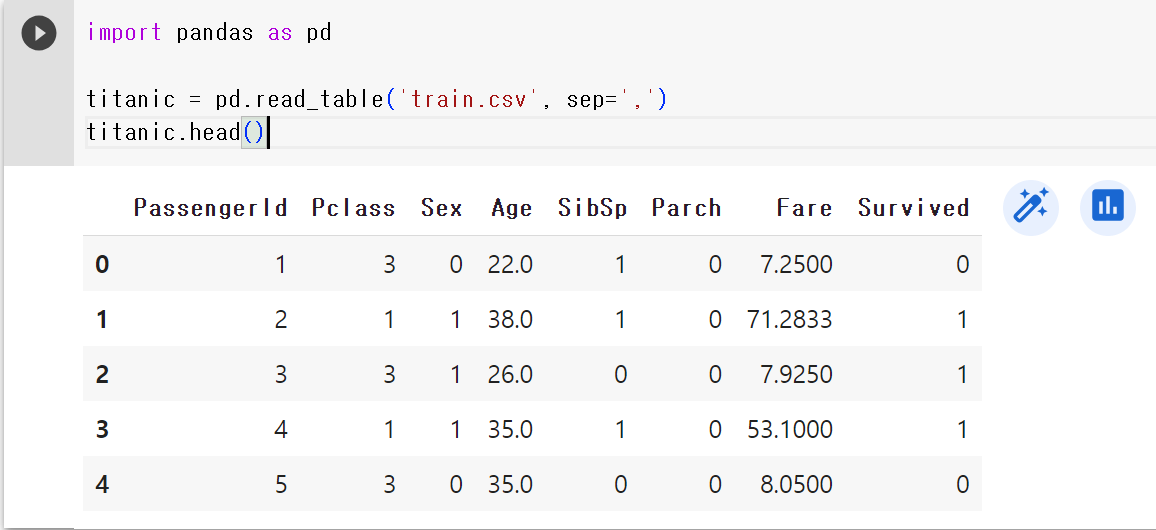
titanic = pd.read_table('train.csv', sep=',')- 데이터 확인
titanic.head(n)
# 처음 n줄의 테이터를 출력한다.
# 아무 입력이 없을 경우 5줄을 기본으로 출력한다.
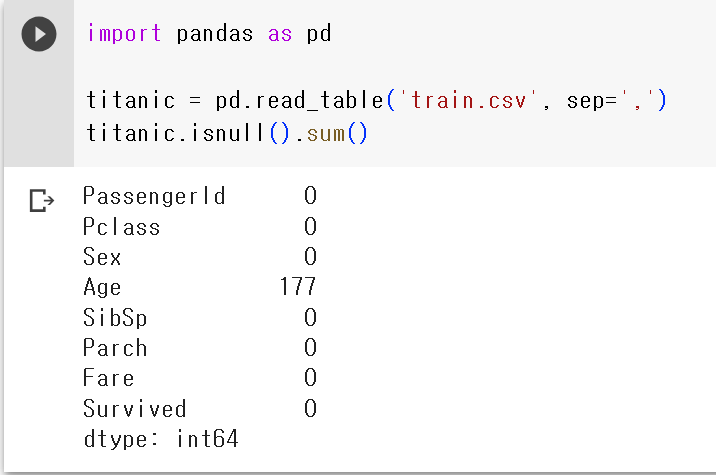
3) 데이터 중 결측치 확인하고 결측치 값은 없애주기
titanic.isnull().sum()
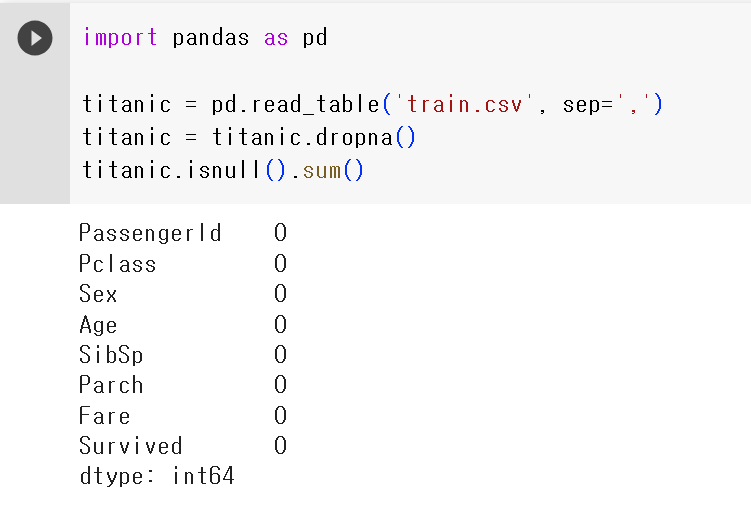
#값이 없는 행의 수를 세서 알려줘라titanic = titanic.dropna() # dropna()로 결측치 값 없애주기
titanic.isnull().sum() # 결측치가 잘 빠졌는지 확인
4) 데이터 분석하기
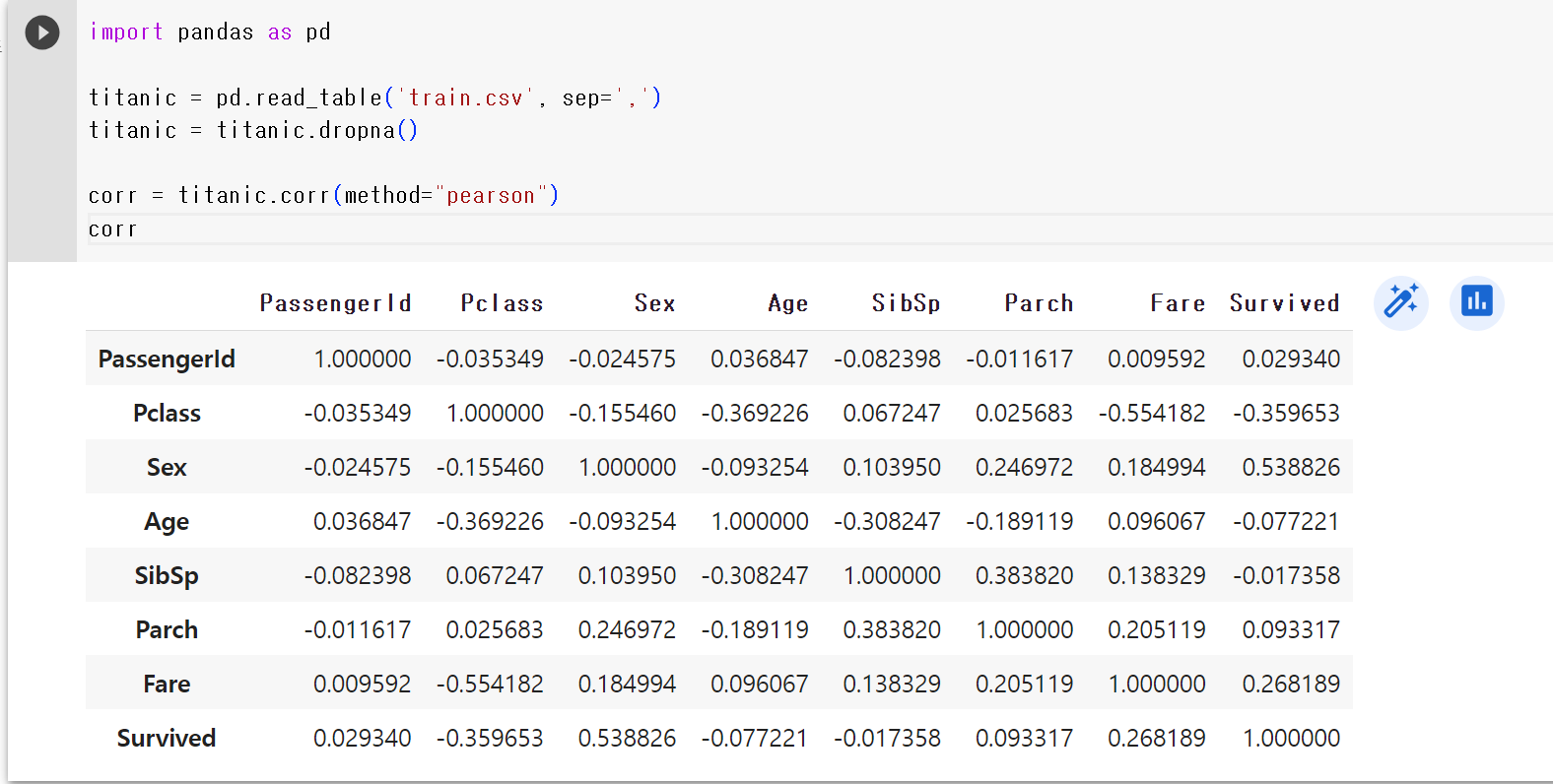
- 상관계수 구하기 : corr 함수 사용, method는 pearson 방법으로
corr = titanic.corr(method="pearson")
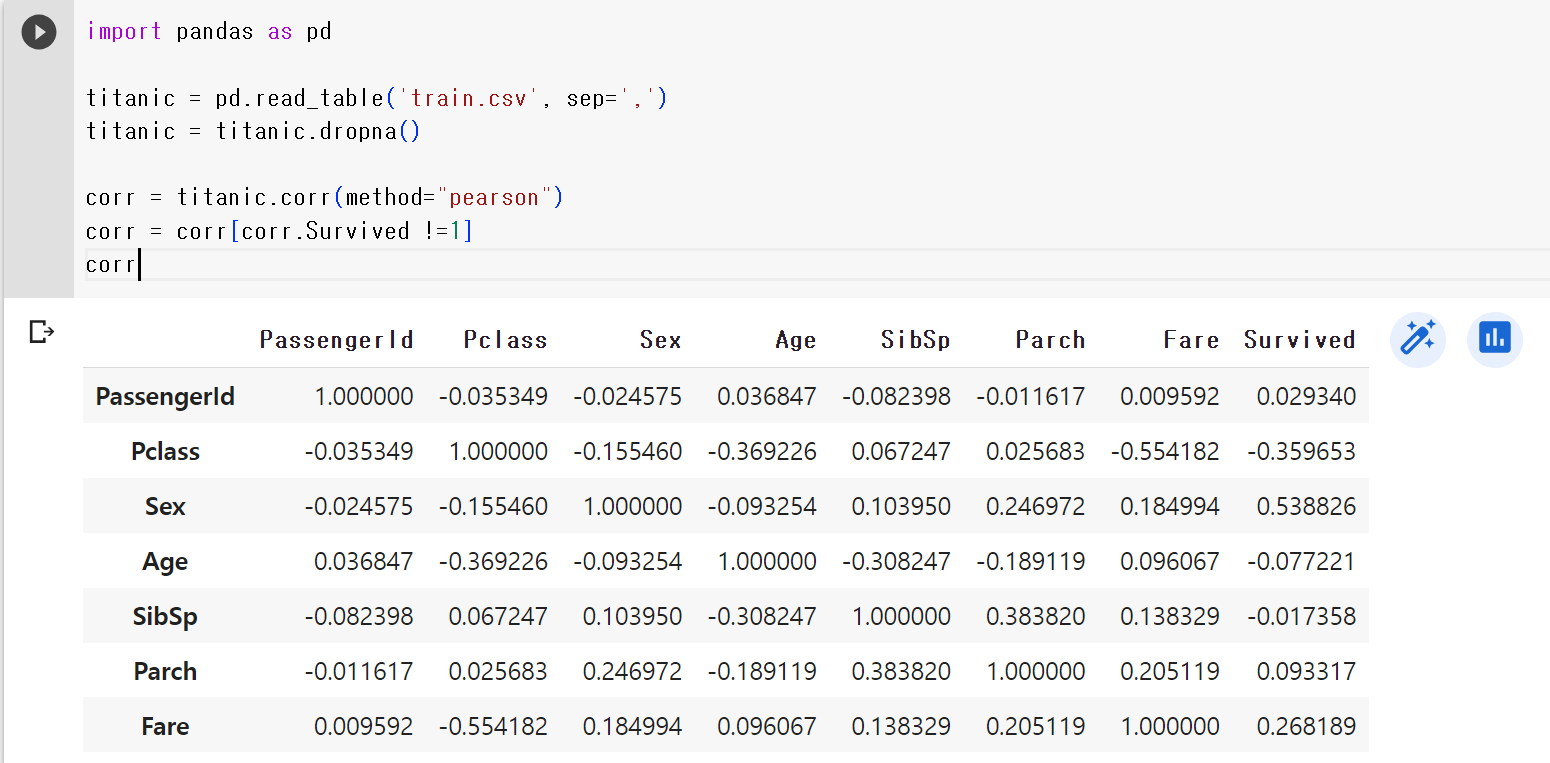
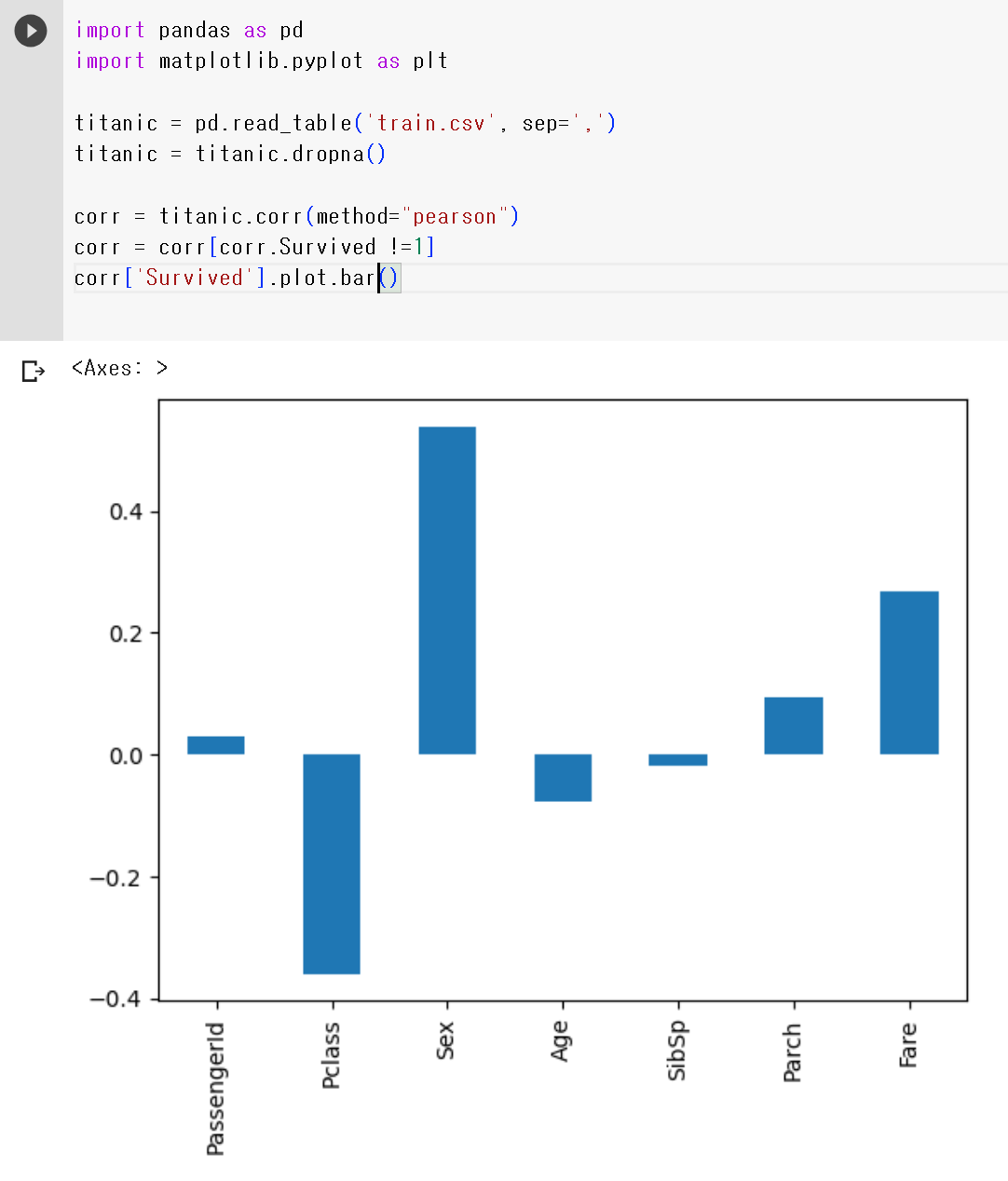
corr- Survived에 대한 상관계수만 보고 싶으므로 Survived에 대한 항목은 제거해준다.
corr = corr[corr.Survived !=1] #상관계수 값이 1이 아닌 애들만 다시 corr에 선언
5) 데이터 시각화하기
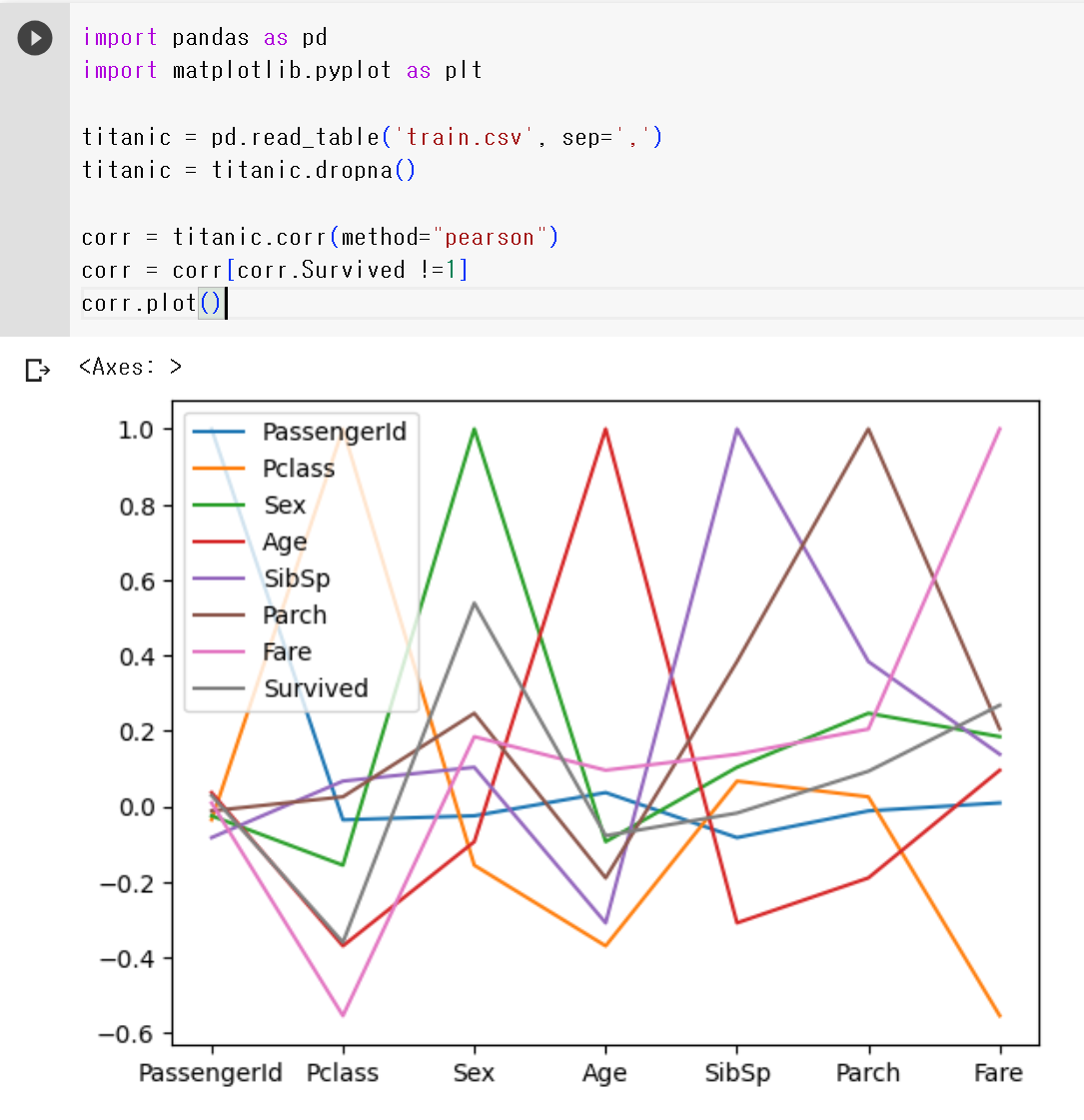
- matplotblib 사용 선언하기
import matplotlib.pyplot as plt- 그래프 그리기
corr.plot()
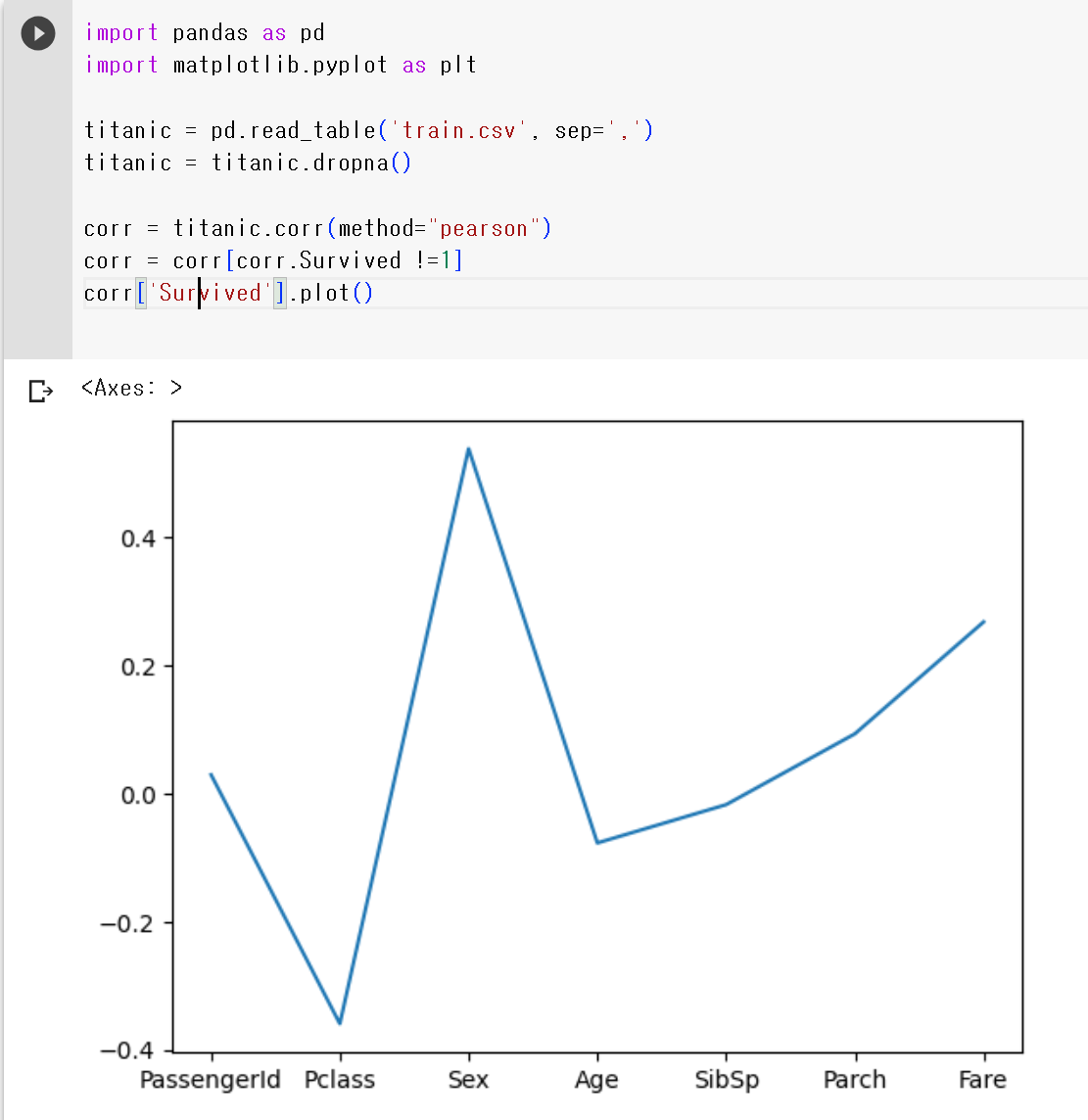
- Survived에 대한 값만 볼 수 있도록 수정
corr['Survived'].plot()corr['Survived'].plot.bar() #막대그래프로 수정
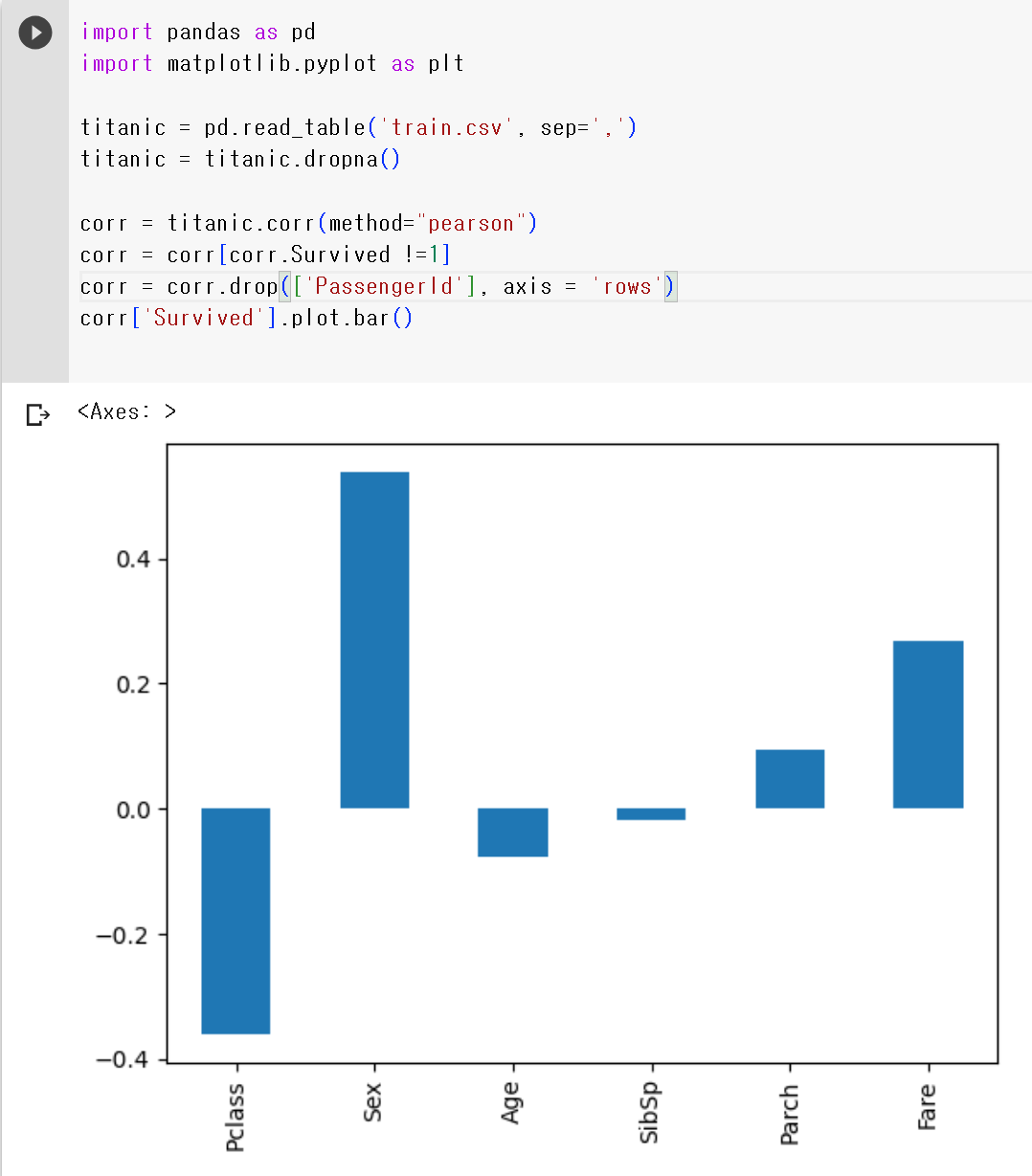
- PassengerId는 분석할 필요가 없으므로 지워준다.
corr = corr.drop(['PassengerId'], axis = 'rows')
corr['Survived'].plot.bar()6) 결과 분석하기
- 성별이 높은 상관관계를 보였고, 그 다음으로 좌석등급과 요금이 뒤따랐다.
예제1) 추가분석
더보기

가설 : 나이와 생존률이 관련이 있을 것이다. 나이가 어린 사람들이 살아남았을 가능성이 더 높을 것이다.
1) 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns- numpy : 데이터 연산을 도와주는 라이브러리
- seaborn : 시각화 도와주는 라이브러리
2) 데이터 불러오기, 확인 및 결측치 제거하기 (동일)
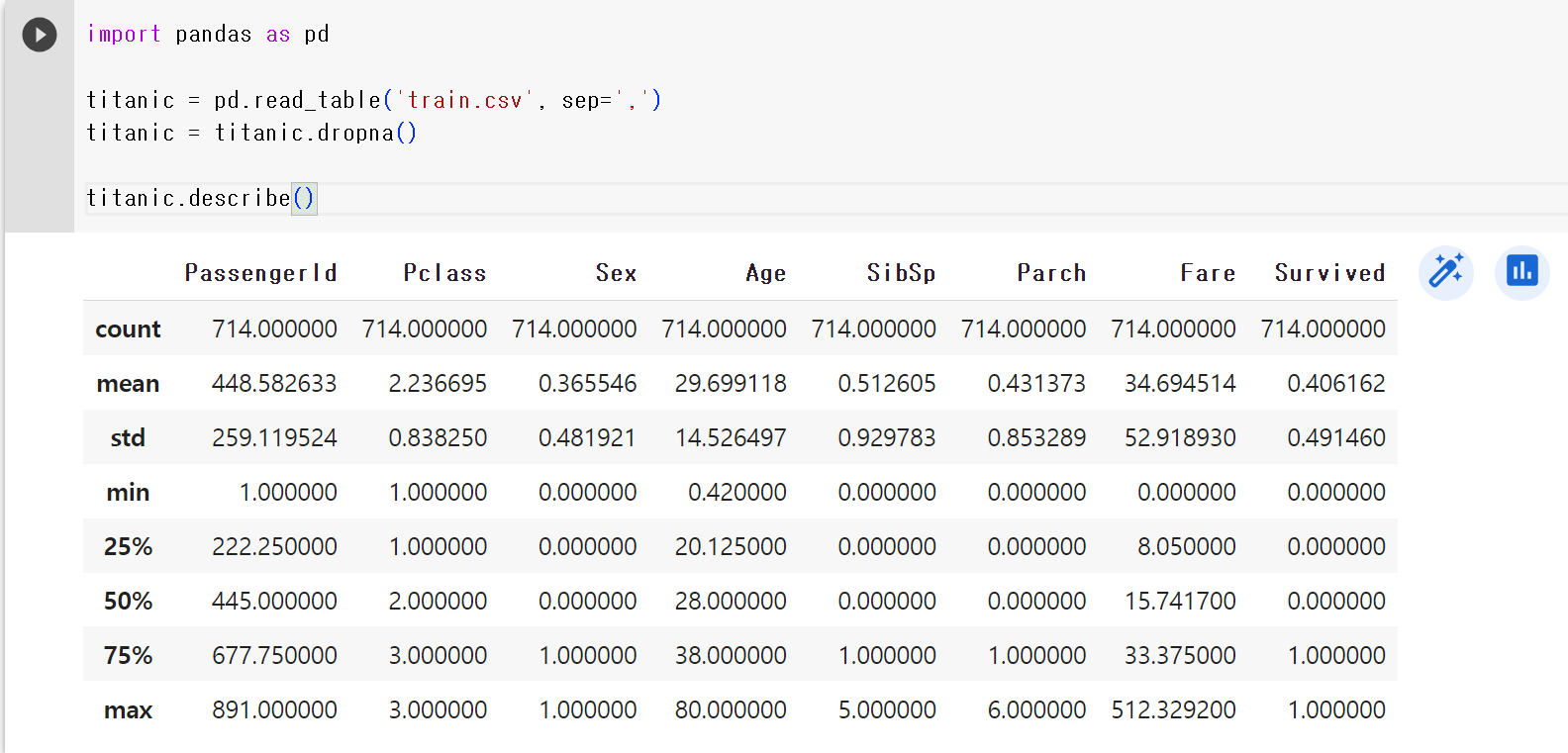
3) 통계치 요약하기
# 대략적인 값을 확인해보자
titanic.describe()
4) 시각화하기
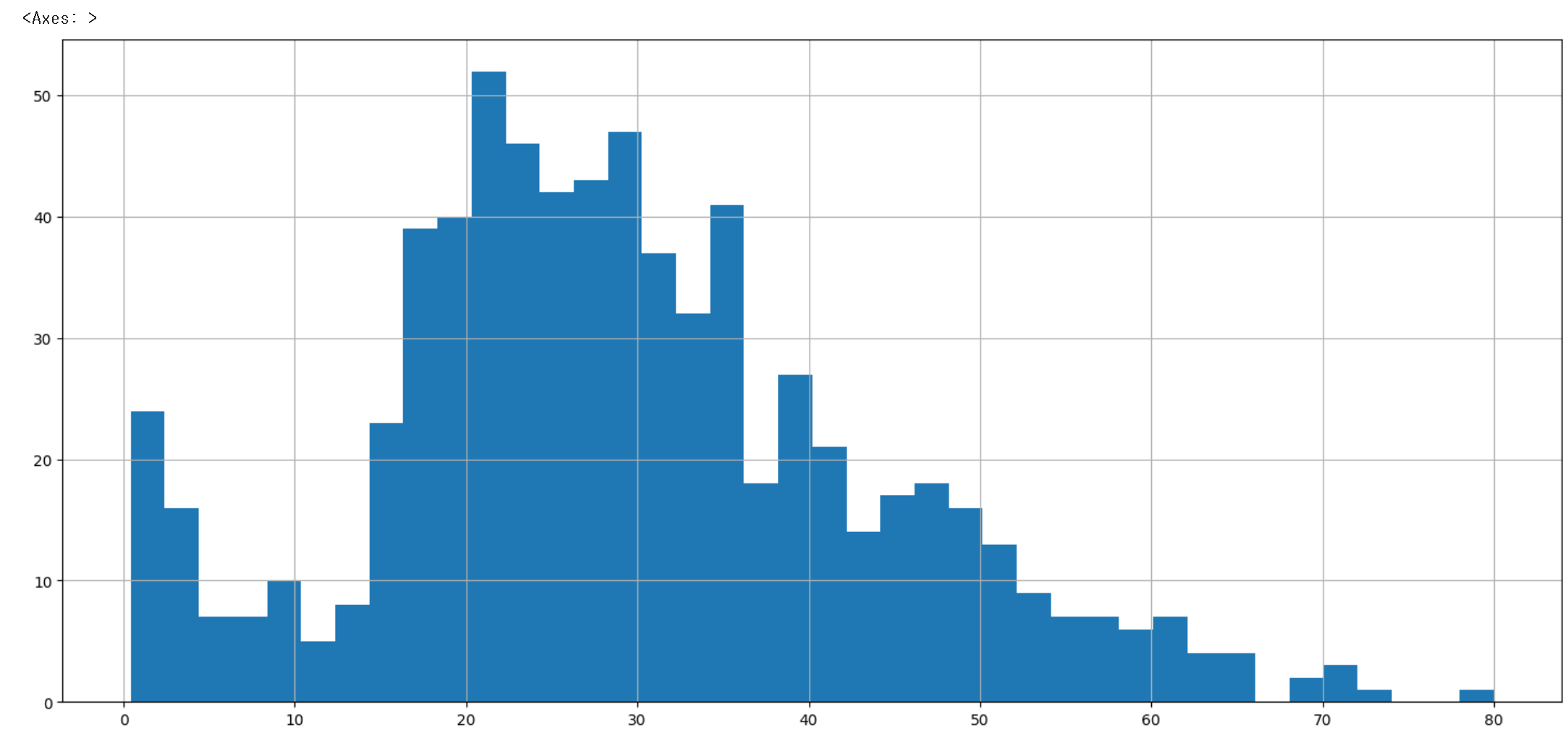
- Matplotlib의 hist() 함수는 히스토그램을 그려준다.
- bins : 가로축 구간의 개수
- cumulative= True or False : 누적 히스토그램 그리기
- grid는 눈금 표시하기
- figsize : 표 크기
#나이별로 히스토그램 구하기
titanic['Age'].hist(bins=40,figsize=(18,8),grid=True)
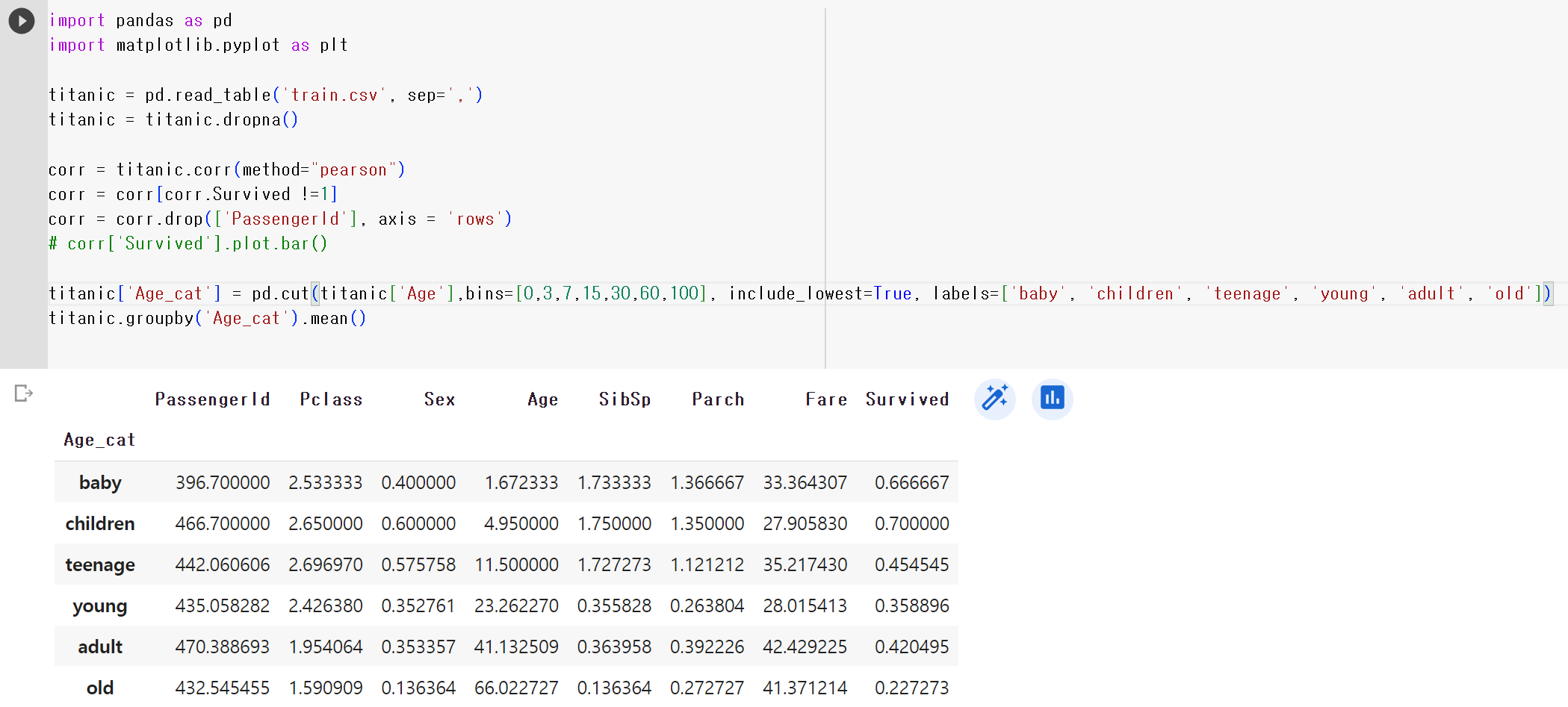
5) 나이별 구분 및 생존율 확인하기
#나이별 구분 및 각 나이별 생존율 확인 하기
titanic['Age_cat'] = pd.cut(titanic['Age'],bins=[0,3,7,15,30,60,100],include_lowest=True,labels=['baby','children','teenage','young','adult','old'])
#연령대를 기준으로 평균 값을 구해 볼수 있어요!
titanic.groupby('Age_cat').mean()- groupby() : 원하는 칼럼을 기준으로 그룹을 묶을 수 있도록 만드는 함수
- titanic.groupby('Age_cat').mean() : 그룹별 평균 구하기
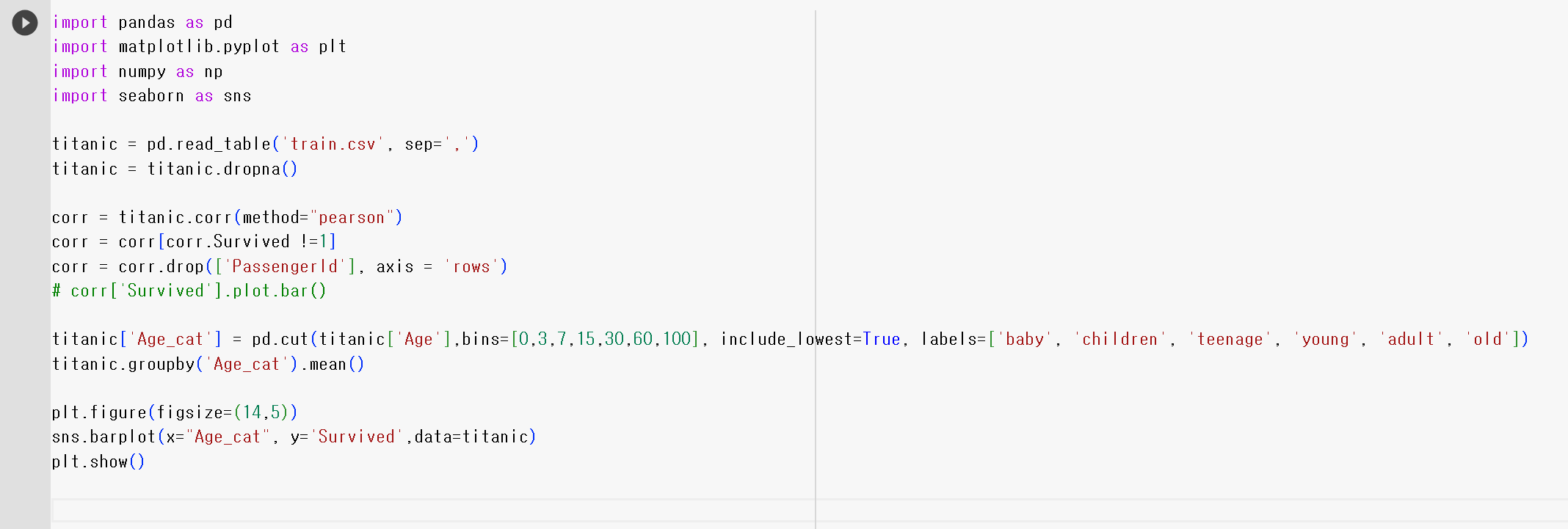
6) 나이대와 생존율 관계 그래프 그리기
# 그래프 크기 설정
plt.figure(figsize=(14,5))
# 바 그래프 그리기 (x축 = Age_cat, y축 = Survived)
sns.barplot(x='Age_cat', y='Survived', data=titanic)
# 그래프 나타내기
plt.show()
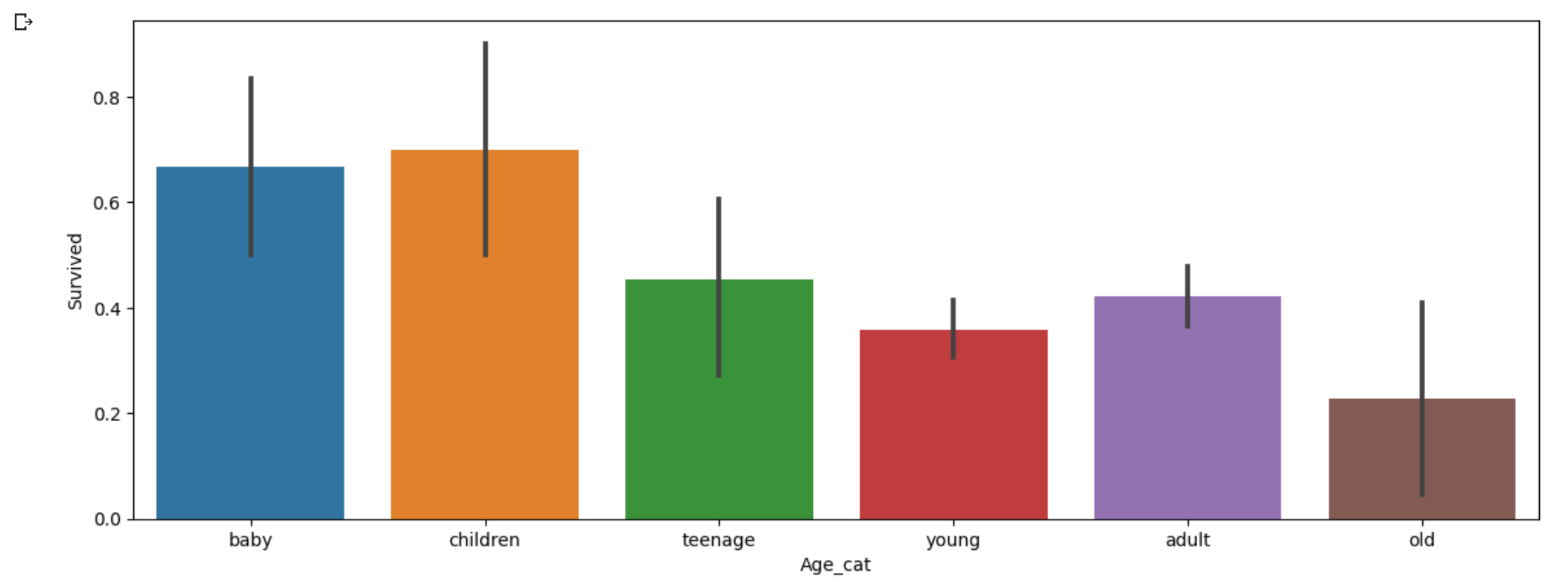
7) 데이터 해석하기, 결론 도출
- 생존율을 봤을 때, 연령대가 낮은 baby, children 그룹이 높았고, 연령대가 높은 old 그룹은 낮았다.
- 나이가 어린 사람들이 더 많이 살아남았음을 알 수 있다.
예제2) 당뇨병 발병 사례
더보기

1) Pandas, Matplotlib import하기
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
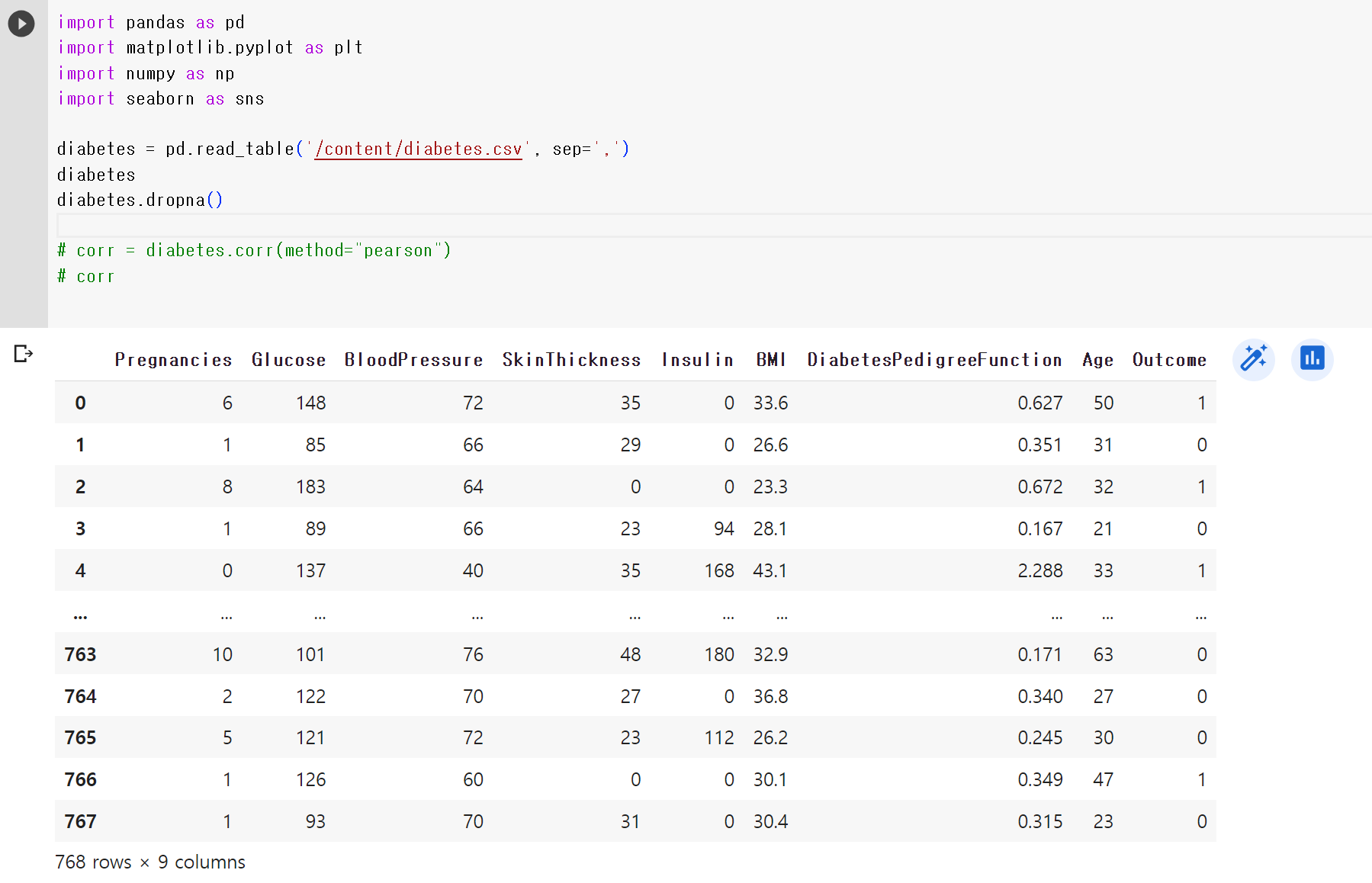
2) 데이터 가지고 와서 table로 읽기
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
diabetes = pd.read_table('/content/diabetes.csv', sep=',')
3) 데이터 결측치 없애주기
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
diabetes = pd.read_table('/content/diabetes.csv', sep=',')
diabetes
diabetes.dropna()
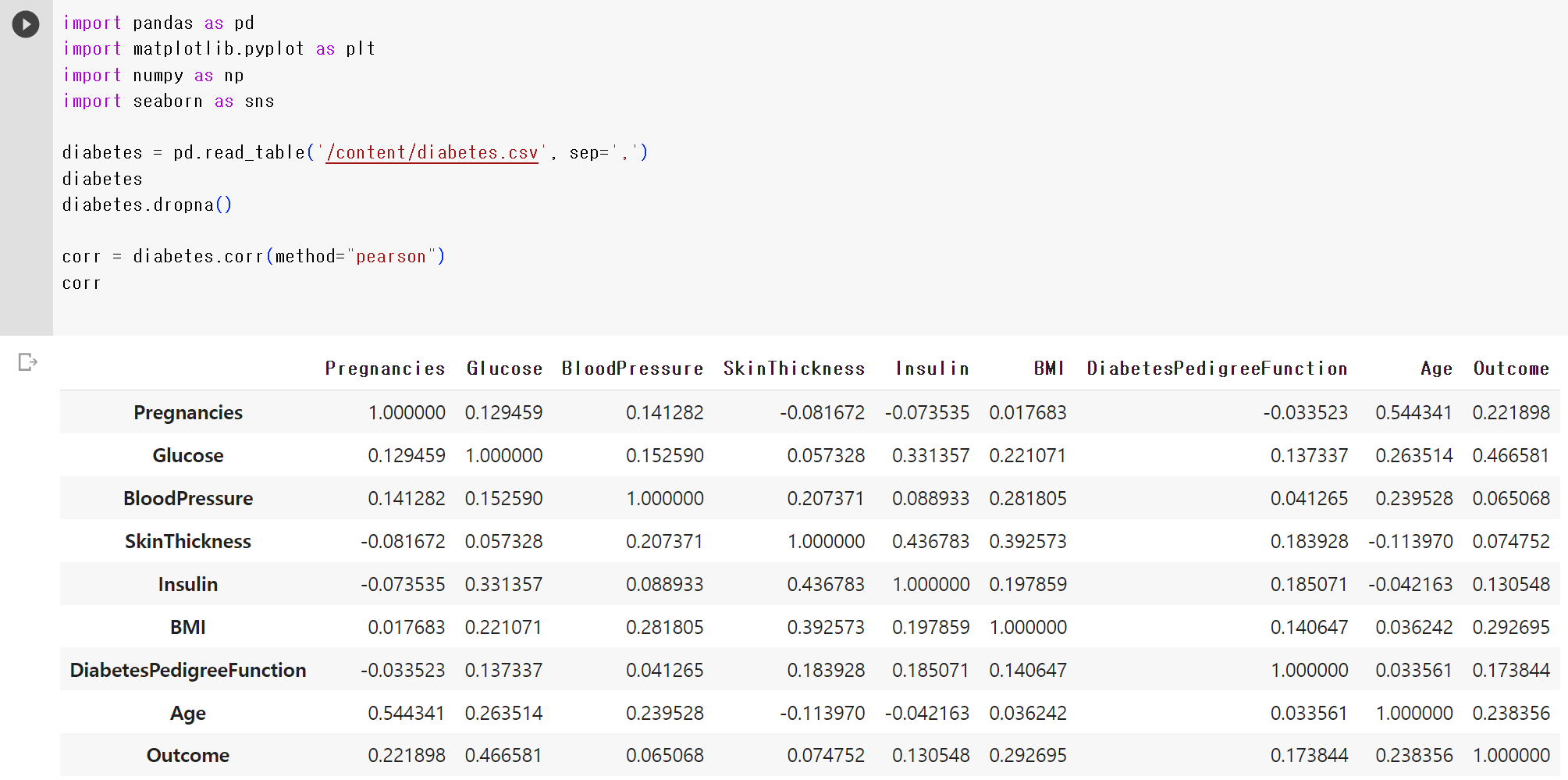
4) 데이터 분석하기
- 상관계수 구하기
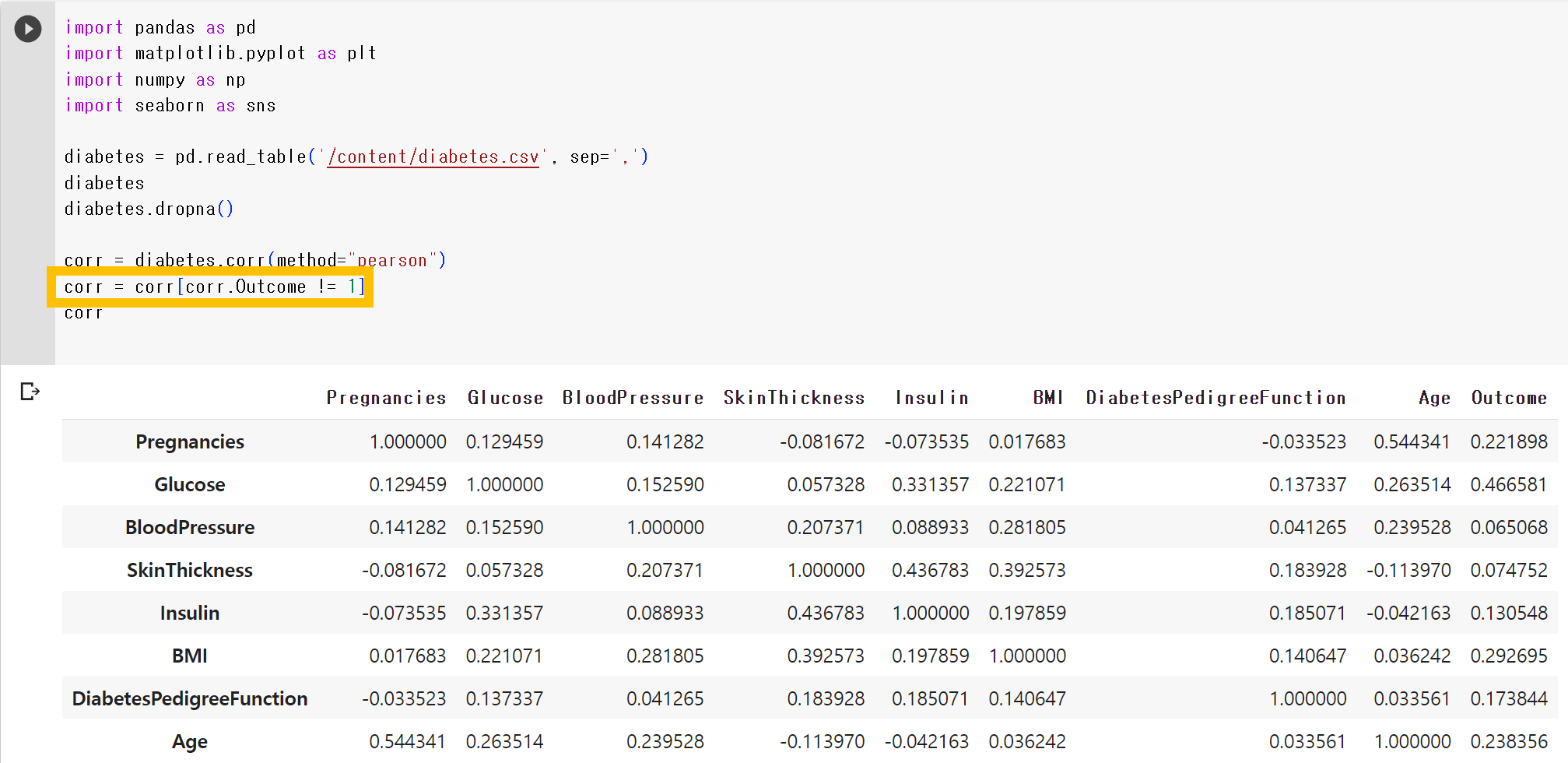
- Outcome이 자기 자신과 가지는 상관계수는 1이므로 Outcome 값은 하나 없애준다.
5) 시각화하기
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
diabetes = pd.read_table('/content/diabetes.csv', sep=',')
diabetes
diabetes.dropna()
corr = diabetes.corr(method="pearson")
corr = corr[corr.Outcome != 1]
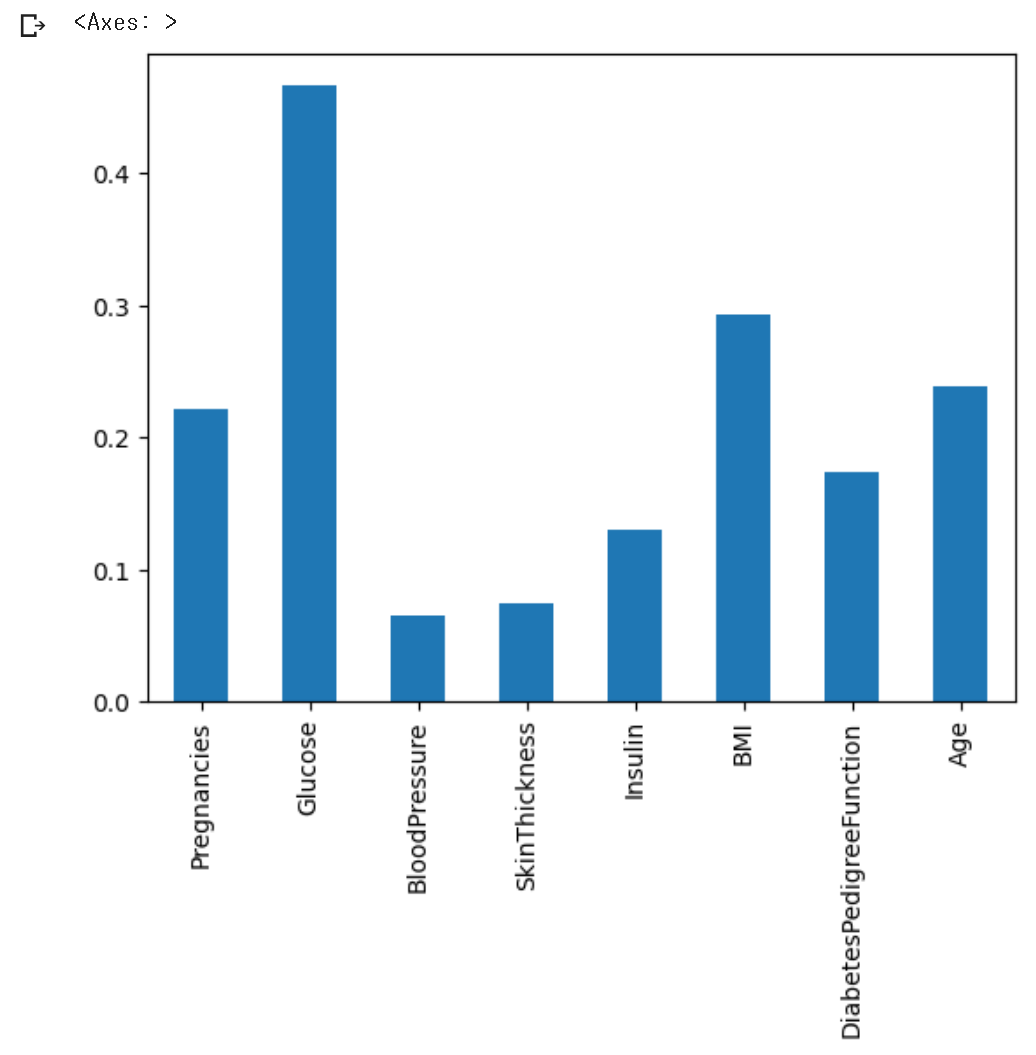
corr['Outcome'].plot.bar()
6) 결과 해석하기
- 발병률과 가장 높은 상관계수를 가진 값은 글루코스였다.
- 글루코스가 당뇨병 발병과 유의미한 관계를 갖는다고 볼 수 있다.
'Programming > DATA' 카테고리의 다른 글
| [1] 파이썬 시작하기 (0) | 2023.07.12 |
|---|---|
| [0] 데이터 분석 기초 : 엑셀 상관관계, 상관계수 분석 + 차트 시각화 (0) | 2023.07.12 |
'Programming/DATA' Related Articles
more
